四、微服务:负载均衡算法
一、简介
负载均衡是提供高可用服务的关键基础组件,核心作用就是将大量请求以合理的方式分配到多个执行单元上去执行,达到最优化的资源使用方式,避免多个单元同时发生过载。
比如我们从注册中心查询到10个可用节点,通过负载均衡器,可以将我们的10个请求,以一种策略打散到不同的可执行节点上,保障可用性。
具体详细介绍:负载均衡
二、模式
负载均衡一般有两种模式:客户端负载均衡、服务端负载均衡。
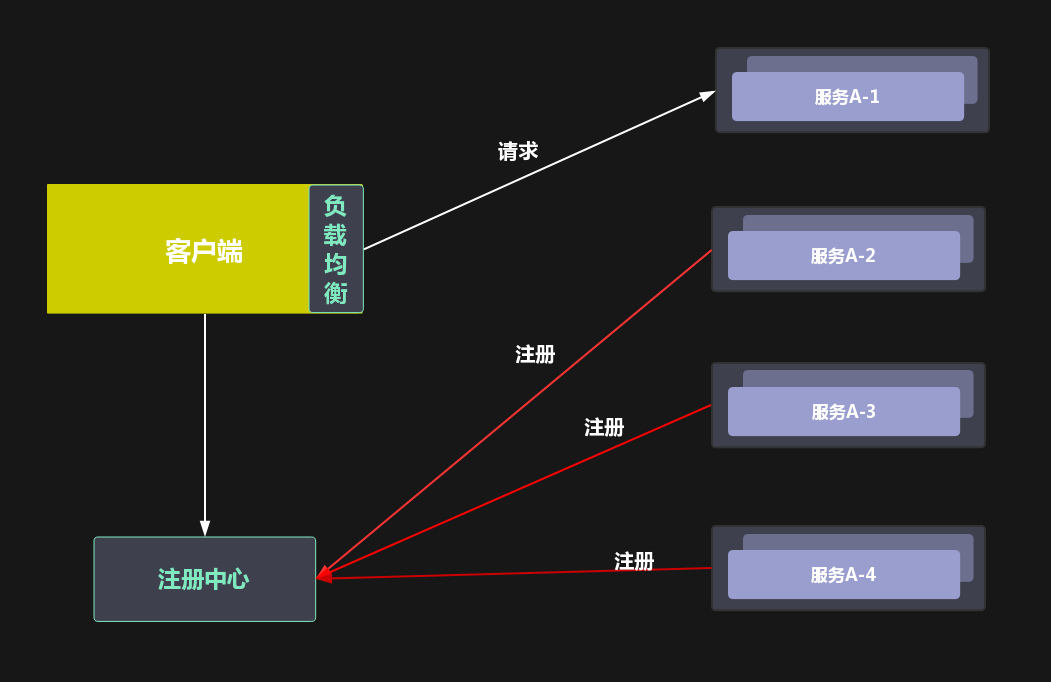
2.1 客户端模式
客户端直接从注册中心获取可用节点,每次请求,通过负载均衡器选出一个可用节点进行请求。这种优势在于服务具备一定弹性,没有中心瓶颈,但是会增加客户端的复杂程度。
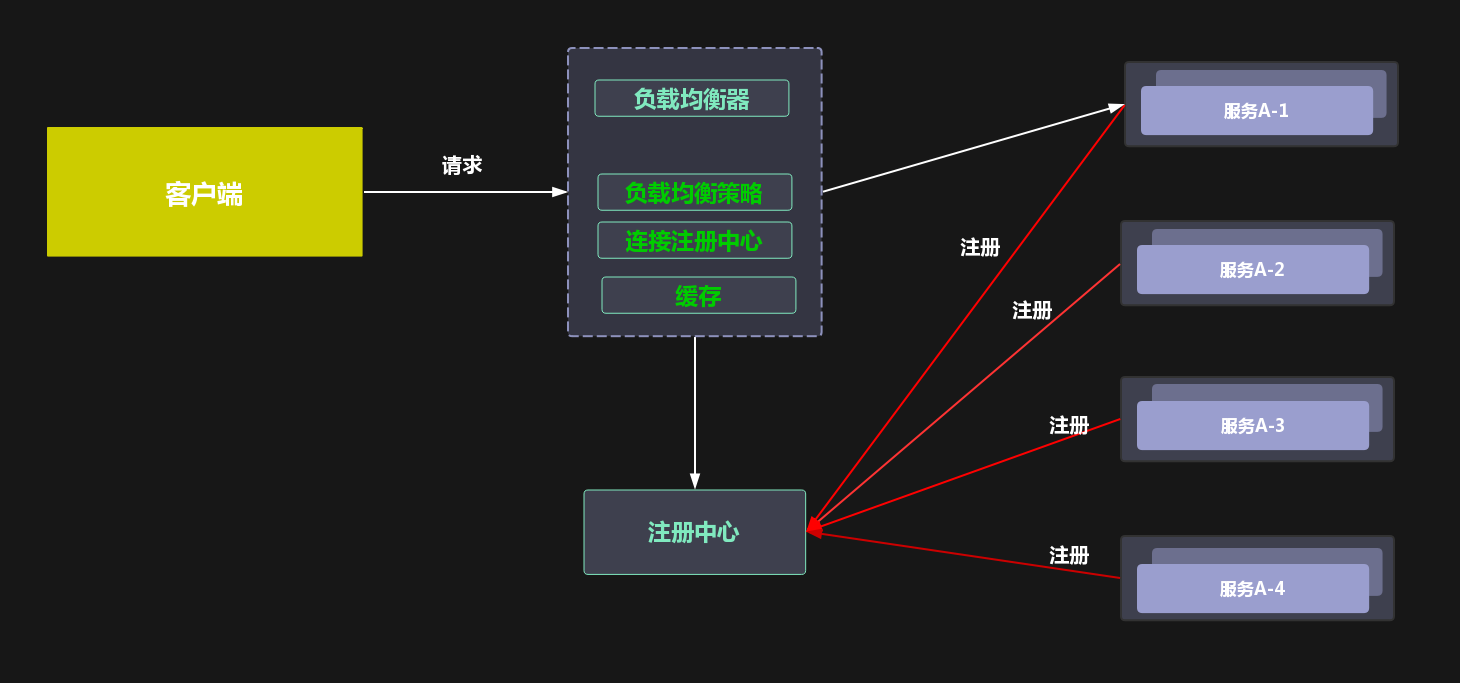
2.2 服务端模式
客户端通过proxy的模式做负载均衡策略。但是存在中心节点,存在性能瓶颈,但是优势很明显,负载均衡的策略对客户端来说是无感知的。
三、负载均衡算法
3.1 随机算法
从可用节点中随机抽取一个节点,10个可执行单元的话,随机生成一个1~10之间的数。随机算法在请求量比较大的情况下,所有节点被访问的概率是相同的。
算法实现
1 | func RandomLB(node []string) (string,error){ |
3.2 轮询算法
轮询算法就是把所有可用节点放在一个数组里顺序访问,轮询算法可以保证所有节点被访问的概率是相同的。
1 | func PollingLB(node []string,curIndex int) (string,int,error){ |
3.3 加权轮询算法
加权轮询算法在轮询算法的基础上增加权重,比如A,B,C三个节点,权重比是3:2:1,按照这个权重,客户端如果请求6次,那么请求到各个节点的状态因该是 A、A、A、B、B、C。但是为了让流量均匀访问,应该是这种状态,A、B、A、C、A、B。
仿照Nginx的加权轮询算法的实现
字段描述:
- current_weight:当前权重
- effecitve_weight:有效权重
- weight:权重
实现
- 遍历所有节点,对每个节点执行node.current_weight += node.effecitve_weight,同时累加effective_weight计为total
- 从所有节点中筛选current_weight最大的节点。
- 更新current_weight节点node.current_weight -= total。
具体实现如下:
1 | type Node struct { |
3.4 一致性hash算法
使用一致性hash使同一来源的请求路由到固定的节点,只有当节点不可用的情况下,才会重新路由到新的节点上。
最简单的hash算法,我们可以通过用户的账号ID或者会话ID计算hash值,然后与节点数取模运算,得到的结构就是应该被路由到的服务器编号。
公式:hash(object) % N
1.剔除一台机器:
公式:*hash(object) % (N - 1)
2.增加一台机器
公式:*hash(object) % (N + 1)
根据上面的公式,增加机器,和剔除机器,如果是有状态服务,需要把对应的状态资源进行迁移。
具体实现:
1 | func HashLB(nodes []string, id string) string { |