5.1、简介
单体服务被拆分为多个服务,调用关系错综复杂,突发大流量很可能把当前一些服务压垮,造成资源的耗尽。甚至直接导致雪崩效应。
服务限流可以把这种突发流量超出处理范围的部分丢弃掉,或者阻塞他们在队列里。避免雪崩。这个时候通过监控机制,我们可以完成扩容等方案,进而处理流量的暴增。
5.2、限流策略
限流为了限制单位时间内最大的处理速度。保证在服务不被压垮的情况下,以最大速率处理请求。一下场景会触发限流
- 拒绝服务,感知流量暴增的情况下,限制一些高频请求的客户端。
- 延时处理,缓冲队列中积压了大量的请求,并且已经达到队列上限。此时应该做限流处理。
- 服务降级,cpu等资源负载,此时应该触发限流。
5.3、限流算法
5.3.1、计数器
维护一个计数器,来一个请求,计数器加一,处理完一个请求,技术器减一。设定一个阈值,计数器达到阈值,触发限流逻辑。
优势:简单
缺点:缺点很明显,就是突发的并发大流量,直接就触发了限流。
5.3.2、队列算法
维护一个队列,请求速度突增或下降,服务总是按照一定速率去处理。队列的大小可以设置,超出限制可以直接拒绝,知道队列出现空间。
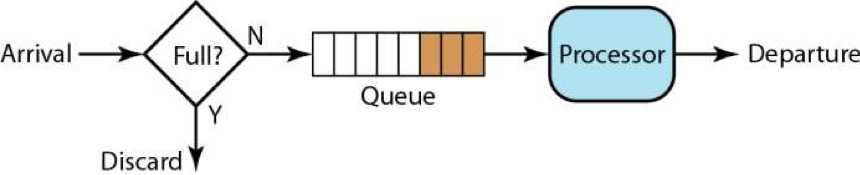
扩展:
- 队列可以设置优先级,程序优先处理高优先级请求。这种的缺点会造成优先级低的队列始终得不到处理,在那里死等,知道客户端提示超时。
- 队列可以设置权重,例如设置A、B、C三个队列的权重3:2:1,那么服务可以先处理Ade三个请求,在处理B的2个请求,在处理C的1个请求。避免出现优先级的问题。
优势:简单
缺点:无法准去预估队列空间的大小,设置大了,在没有实施限流之前,服务就垮了。设置小了,在没达到系统瓶颈的时候,可能触发了限流策略。需要提前对服务做好压测
5.3.3 漏斗算法
5.3.3.1 介绍
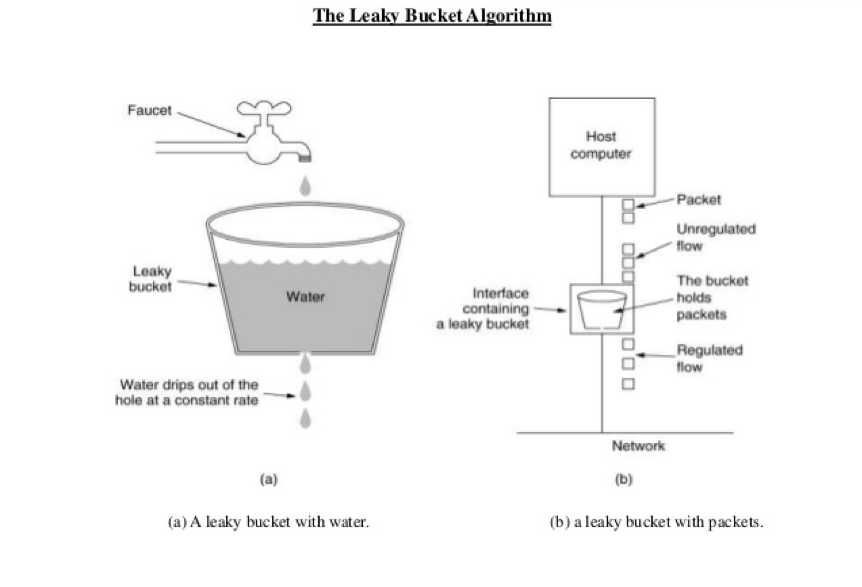
很经典的算法,将请求流量比作水流入,将处理速度比作水流流出。流出速度按照固定速率。
- 流入速率<流出速率,漏斗里肯定不会积水,也就是不会触发限流。
- 流入速率>流出速率,漏斗肯定会积水,直到溢出。这个时候触发限流。
溢出部分的请求将被拒绝。
优势:以恒定速率处理请求,避免服务被压垮
缺点:无法应对突发流量,突然间的陡增,服务也会按照约定好的速率去处理。
因为漏斗算法还是很经典的,我们看下实现方案,其实就是在队列算法上加一个限速器。
源码地址:leakybucket
5.3.3.2 实现
这里只简单描述算法的实现过程,更详细的大家可以去看源码.
1 | type bucket struct { |
- capacity :容量,漏斗最大的装水量,也就是单位时间内最大请求量。
- remaining:漏斗中还能容纳多少水,也就是单位时间内还能处理的请求量。
- reset :重置时间,每经过一次单位时间,重置remaining,设置remaining = capacity
- rate :速率,也就是单位时间
- mutex :锁
1、首先通过Create函数创建漏斗。
1 | func (s *Storage) Create(name string, capacity uint, rate time.Duration) (leakybucket.Bucket, error) { |
唯一需要特殊描述的就是remaining初始值就是漏斗的容量,reset的初始值就是当前时间加rate,比如现在是10:21:00,速率设置为1s,那么在10:21:01的时候就可以重置remaining。清晰一个概念,程序单位时间内的最大处理数为capacity,remaining为0时触发限流。当前单位时间过后,取消限流,也就是重置remaining
2、通过Add函数加水
1 | func (b *bucket) Add(amount uint) (leakybucket.BucketState, error) { |
- 当前时间>reset,重置
- 请求数>remaining,限流
- 更新remaining。
5.3.4、令牌桶算法
5.3.4.1介绍
另一个经典的限流算法。
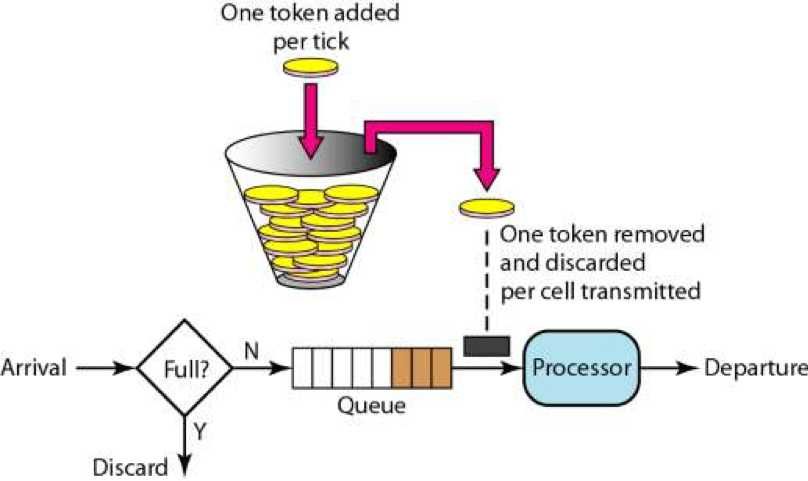
请求先去获取令牌,获取到了进入逻辑处理,获取不到被阻塞或者快速拒绝。相对于漏斗算法很大的区别就是,漏斗算法总是以恒定的速率去处理请求。但是令牌桶算法在流量小的时候可以积累令牌。大流量突发可以发光所有令牌,瞬间处理大量请求,没拿到令牌的部分触发限流。
但是processor的处理速度因为queue的存在。无论桶里有多少令牌,队列里有多少请求,漏斗算法与令牌桶算法最终都会受限于processor自身的处理速度。但是如果processor如果仅仅是起到一个转发的作用,比如像Nginx一样提供一个网关的能力。那processor自身就不会有什么瓶颈,会很快处理掉queue的请求。这个时候漏斗算法与令牌桶算法就体现出不一样的效果了。
5.3.4.2、实现
golang的基础库z1有一个很经典的实现
令牌通算法使用golang.org/x/time/rate
5.3.5、基于响应时间的动态限流算法
以上算法有一个缺点,就是需要通过压测来找到限流的阀值。有没有一种能够动态根据响应时间来动态设定阀值,进而动态感知服务的阀值。
这方面很经典的算法就是TCP的拥塞控制算法了。TCP通过RTT来探测网络的性能和延时,进而调控窗口大小,让发送的速率与适应当前的网络环境。具体的算法实现可以参陈皓老师的TCP的那些事(下)。所以我们可以在我们的限流设计中借鉴TCP的拥塞算法。
依赖令牌通算法,动态实时设置rate,就可以实现动态更新限流的速率。令牌通算法使用golang.org/x/time/rate
rate称之为拥塞窗口,简称:cwnd
demo示例:autolimit
5.3.5.1、RTT采用计算
RTT定义为收到请求到请求处理完回包的时延。
首先收集1000次请求数据的RTT,在利用蓄水池算法进行采样,这里采样可以采集50%或80%数据。然后在求样本集合中的平均值。
采集数据:
1 | //采样蓄水池算法 |
样本平均处理:
1 | //平均rtt值 |
5.3.5.2、SRTT与RTO计算
这里我们采用TCP的经典算法先来实现测量RTT与RTO(后面考虑用Jacobson / Karels 算法替换掉)。
SRTT,对RTT进行平滑处理,公式如下
SRTT = ( α * SRTT ) + ((1- α) * RTT),α设置为0.8~0.9,根据α的设定,新的SRTT估值80%来自旧样本,20%来子新样本。
RTO定义为处理超时时间。根据RTT动态变化。公式如下,UBOUND是上线值,LBOUND是下线值,β推荐这职位1.3~2.0之间
RTO = min [ UBOUND, max [ LBOUND, (β * SRTT) ] ]
更新SRTT:
1 | //经典算法 |
更新RTO:
1 | ,//更新rto |
5.3.5.3、慢启动
服务启动后,处理速度慢慢递增,开始处理1个,每当回包一个请求后,cwnd(拥塞窗口)加1。两个回包cwnd加2,也就是呈指数递增。
1 | //慢启动 |
5.3.5.4、拥塞避免
cwnd涨到什么时候呢?在TCP中有一个值ssthresh为65535字节。当超过这个值的时候,增速开始线性增长。每收到一个确认后,cwnd 增加 1/cwnd,8个确认cwnd增加1。
这里我们也模仿TCP的拥塞避免
1 | //拥塞避免 |
5.3.5.4、拥塞处理
就算是拥塞避免处理,也会有RTO超时的时候,那么这个时候,认为当前的环境很差,这个时候ssthresh=cwnd/2,cwnd=1,重新进入慢启动过程
1 | //拥塞阻塞 |
5.3.5.6、快速恢复
在TCP中发生快速重传,TCP任务这种不是很严重的情况,仅仅是部分丢失。对应到我们限流中,我们可以理解其中一,两个的超时其实也不是很严重的情况,不需要直接将cwnd重置为1。
- cwnd = cwnd /2
- sshthresh = cwnd
然后,真正的Fast Recovery算法如下:
- cwnd = sshthresh + 3 * MSS (3的意思是确认有3个数据包被收到了)
- 重传Duplicated ACKs指定的数据包
- 再收到 duplicated Acks,那么cwnd = cwnd +1
- 收到了新的Ack,cwnd = sshthresh ,直接进入拥塞避免的算法了。
在我们的实现中也可以模仿这种策略
1 | //快速恢复 |
5.3.5.6、动态更新
以上所有策略基本上完成了,最后把那些策略进行组合就OK,
1 | //收集rtt |
5.4、总结
限流的设计其实也是为了提升服务的容错性,保证在突发流量的情况下,服务不会过载。为了节省资源,部署服务的时候,同样不可能把一个不常见的峰值作为扩容的标准。限流的设计需要注意以下几点。
- 限流需要设置开关,关闭开关,关闭限流。
- 限流组件的设计要对流量有敏感的感知,否则还没等开始限流,服务已经过载。
- 因为限流被拒绝的服务,可以阻塞住,或者直接返回错误码,客户端可以根据错误码来自定义重试策略。
- 限流需要通知后端服务,如果服务发现限流标识。这个时候自身可以决定是否需要降级,停止一些不重要的请求,提升服务的吞吐量。
限流的方案,计数器,队列,漏斗,令牌通都有各自的应用场景,还有基于响应时间的自动限流策略。