一、简介
熔断基本上是微服务框架中必备的能力,熔断可以有效的起到服务自我保护的能力,在容错设计中,熔断就是为了避免客户端多次执行可能出现错误的操作或频繁请求超时导致cpu过载。
二、熔断设计
熔断设计为了保证服务不断去执行已经出现问题的操作,比如主机A去请求目标主机B,B主机自身出现问题,导致A迟迟得不到正确结果,甚至是直到等到超时才返回,这种操作导致cpu浪费在一些异常情况上。
熔断的原理就是在A与B之间搭建一个proxy,这个proxy计算错误率,失败数,超时数等等,来决定是否快速执行快速失败,快速恢复操作等等。
熔断器内部一般有以下几种状态:
- Closed状态:记录时间内的的失败请求,失败数+1,达到一定数据计算失败率,超过单位时间重置计数。如果达到失败率的阀值,切换状态到Open状态。这个时候所有的请求使用快速失败策略,避免客户端因超时后才得到处理,导致cpu的浪费。与此同时开启一个时钟,Open状态下,时钟超过配置预定的时间,状态切换到Half-Open,提供一次系统修正机会,放行部分请求,如果该请求无异常则切换回closed状态。
- Open状态:该状态下对于A请求B,proxy应该快速失败,而不是真执行请求B的逻辑,如果有缓存的话,可以直接返回缓存(一种优化策略)。
- Half-Open状态:该状态放行部分请求到B,来验证B是否恢复正常,如果正常切换到Closed状态,重置计数器,重置时钟,否则继续切换为Open状态。等待下一次Half-Open验证目标服务是否恢复正常。
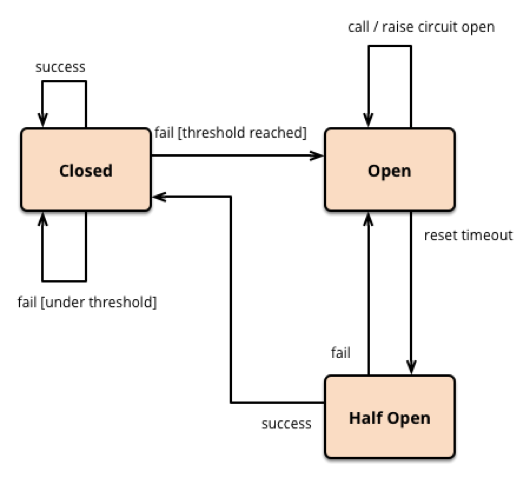
核心能力,熔断设计可以针对已知的错误操作快速响应,不必等到目标主机返回或者超时在处理,并且拥有恢复验证的能力。
三、Hystrix使用
hystrix-go是Netflix开源的容错框架Hystrix的golang版本,能够隔离远程系统、服务或第三方库的访问点,停止级联故障,并在分布式系统中提供故障恢复能力。
Hystrix提供两个接口,一个同步请求,一个异步请求。
1 | func Do(name string, run runFunc, fallback fallbackFunc) error //同步 |
demo
1 | func main() { |
四、hystrix-go实现
以下是hystrix的实现逻辑。
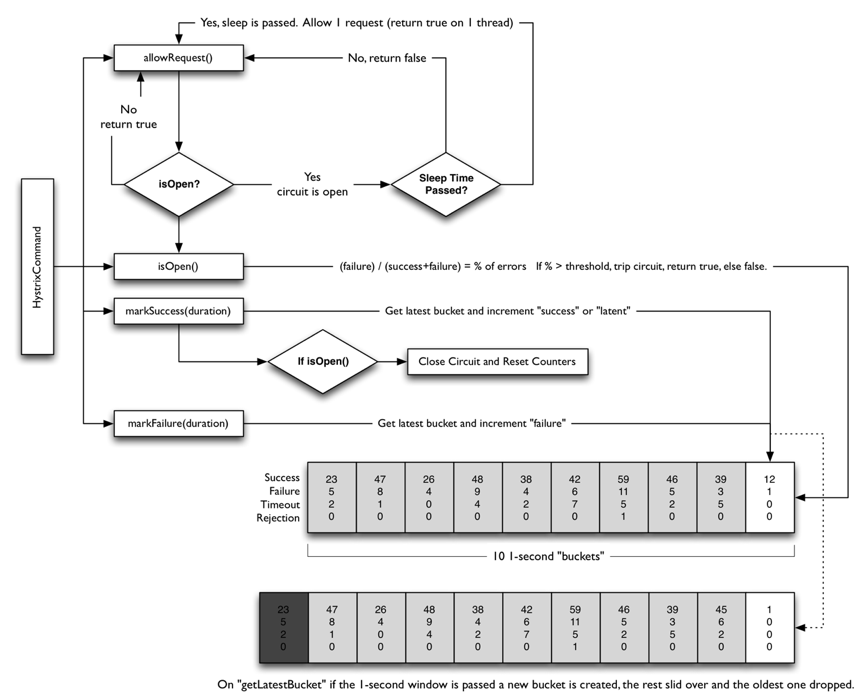
一下代码分析只列出关键逻辑代码,详细设计可以下载源码自己观看。
4.1、AllowRequest
首先通过AllowRequest判断是允许通过,如果允许则放行,否则执行其他相关逻辑(快速失败以及自定的fallbackFunc)。通过IsOpen()加载配置来判断当前是否处于Open,处于Open则不允许该请求发生,快速响应错误。
1 | func (circuit *CircuitBreaker) AllowRequest() bool { |
4.2、IsOpen
1 | func (circuit *CircuitBreaker) IsOpen() bool { |
在切换到open状态下,之前介绍过需要同时设置时钟,用于计算是否达到SleepWindow,如果达到则切换到Half-Open状态,提供一次修正机会。
1 | circuit.openedOrLastTestedTime = time.Now().UnixNano() |
4.3、allowSingleTest
allowSingleTest其实就可以理解为Half-Open状态的切换。
1 | func (circuit *CircuitBreaker) allowSingleTest() bool { |
4.4 Timeout
其中还有一个关键设计就是超时快速返回。原理很简单,就是在执行runFunc的时候开启一个计时器。达到之前设置的Timeout时长。就给errChan赋值快速返回错误ErrTimeout。
1 | go func() { |
4.5 总结
hystrix的关键就是弄清Closed、Open、Half-Open之间的切换流程。
还有一些协成池的设计,来设计同一个command最大的并发次数。可以阅读下源码。hystrix自身在内存中维护一个数组,通过reportAllEvent来统计上报记录。超出统计时长的部分将会被删除。
五、设计重点
- 业务侧需要根据错误类型来决定是否重试。比如Timeout错误就没有必要重试,很有可能对端处于限流状态。如果重试的话,推荐使用指数级退避重试,例如第一次重试2s后,第二次4秒回后,第三次8秒后。
- 添加详细的日志监控,记录熔断状态下的执行情况,方便定位问题。
- 一般服务都是多分区部署的的,有时候可能是其中一台机器出现问题。所以需要对单一熔断进行区分。避免一台机器触发熔断open状态,影响其他分区,导致所有分区都出现。
- 提供一个强制切换熔断器到closed状态的机制。服务修复后,强制将熔断切换到closed状态,快速回复系统正常运转。
六、总结
熔断是对于服务自身起到一个容错保护作用,通过阅读Netflix开源的容错框架Hystrix的策略,可以更深刻的理解熔断机制的作用以及设计重点,熔断设计的关键就是三种状态之间的切换
- Closed
- Open
- Half-Open