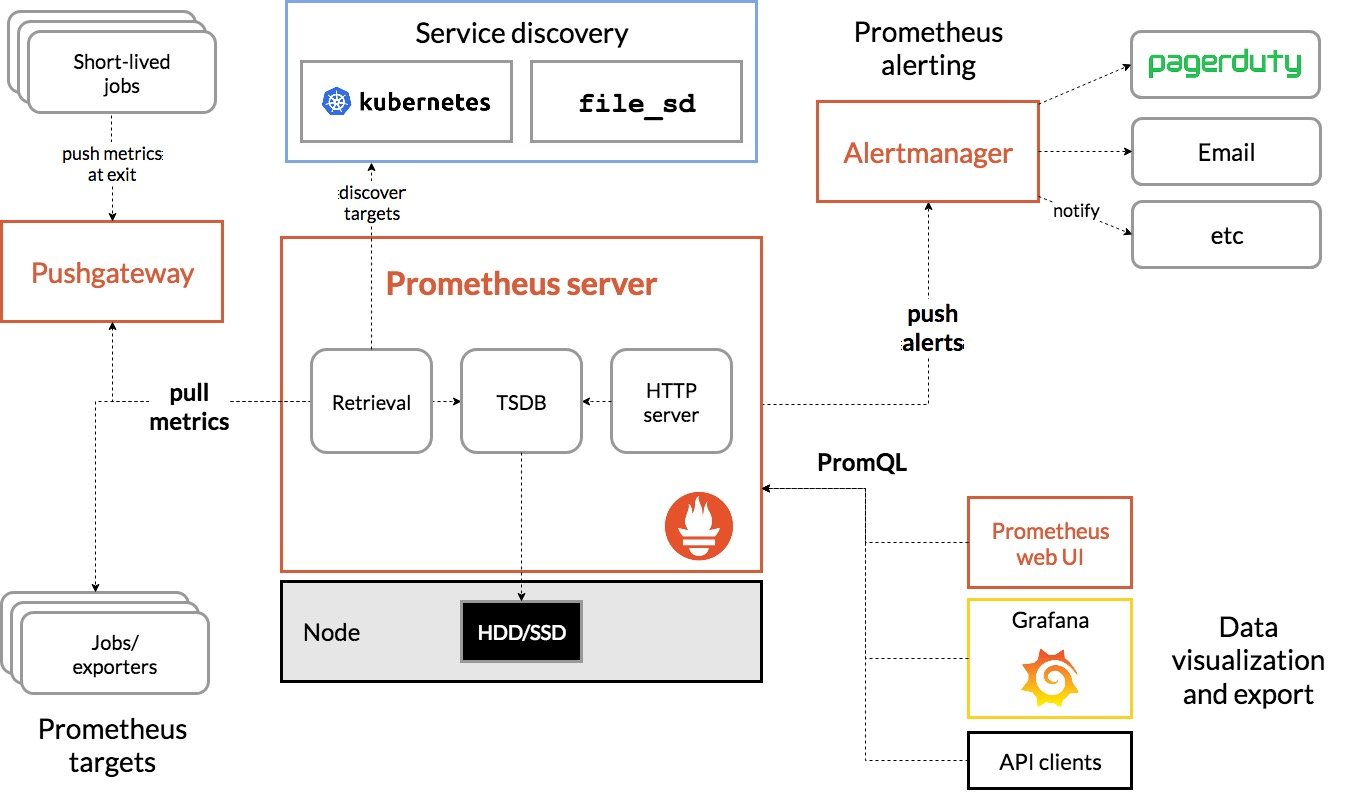
第一次接触Prometheus就被深深吸引,决定阅读源码,了解它的设计方式。首先分析的是pull metrics部分,讨论Prometheus是如何从目标点采集数据的。
1.1、简介
Prometheus采集数据使用pull模式,通过HTTP协议去采集指标,只要应用系统能够提供HTTP接口就可以接入监控系统。
拉取目标称之为scrape,一个scrape一般对应一个进程。如下为scrape相关的配置。
配置文件:
1 | scrape_interval: 15s |
该配置描述:每15秒去拉取一次上报数据,拉取目标为localhost:8886。
1.2、源码分析
通过解析Prometheus采集目标数据源码,进一步了解Prometheus是如何完成pull metrics工作的。
1.2.1、读取配置
ScrapeConfig的结构如下:
1 | type ScrapeConfig struct { |
读取配置:
1 | func (m *Manager) ApplyConfig(cfg *config.Config) error { |
Prometheus 中,将任意一个独立的数据源(target)称之为实例(instance)。包含相同类型的实例的集合称之为作业(job),从读取配置中,我们也能看到,以job为key。所以注意job在业务侧的使用。
1.2.2、Scrape Manager
添加Scrape Manager 到 run.Group启动。reloadReady.C的作用是当Manager接收到一组数据采集目标(target)的时候,他需要为每个job读取有效的配置。因此这里等待所有配置加载完成,进行下一步。
1 | g.Add( |
1.2.3、加载Targets
加载targets,如果targets更新,会触发重新加载,reloader的加载发生在后台,所以并不会影响target的更新,(配置文件中配置的target是依赖discoveryManagerScrape.ApplyConfig(c)进行加载的,后面分析target服务发现的时候详细分析)。
1 | func (m *Manager) Run(tsets <-chan map[string][]*targetgroup.Group) error { |
顺着Run继续阅读,reload为每一组tatget生成一个对应的scrape pool管理targets集合,scrapePool结构如下:
1 | type scrapePool struct { |
1.2.4、执行reload
m.reloade的流程也很简单,setName指我们配置中的job,如果scrapePools不存在该job,则添加,添加前也是先校验该job的配置是否存在,不存在则报错,创建scrape pool。总结看就是为每个job创建与之对应的scrape pool
1 | func (m *Manager) reload() { |
1.2.5、创建scrape pool
scrape pool利用newLoop去为该job下的所有target生成对应的loop:
1 | func newScrapePool(cfg *config.ScrapeConfig, app Appendable, jitterSeed uint64, logger log.Logger) (*scrapePool, error) { |
1.2.6、group转化为target
scrape pool创建完成后,则通过sp.Sync执行,使用该job对应的pool遍历Group,使其转换为target
1 | go func(sp *scrapePool, groups []*targetgroup.Group) { |
Sync函数解读如下:
1 | func (sp *scrapePool) Sync(tgs []*targetgroup.Group) { |
1.2.7、生成loop
在sync最后,调用了当前scrape pool的sync去处理all队列中的target,添加新的target,删除失效的target。实现如下:
1 | func (sp *scrapePool) sync(targets []*Target) { |
1.2.8、运行loop
scrape pool对应的sync的实现中可以看到,如果该target没有运行,则启动该target对应的loop,执行l.run,通过一个goroutine来执行
1 | func (sl *scrapeLoop) run(interval, timeout time.Duration, errc chan<- error) { |
1.2.9、拉取数据
依赖scrape实现数据的抓取,使用GET方法。
1 | func (s *targetScraper) scrape(ctx context.Context, w io.Writer) (string, error) { |
1.3、总结
总结看每一个job有一个与之对应的scrape pool,每一个target有一个与之对应的loop,每个loop内部执 Http Get请求拉取数据。通过一些控制参数,控制采集周期以及结束等逻辑。