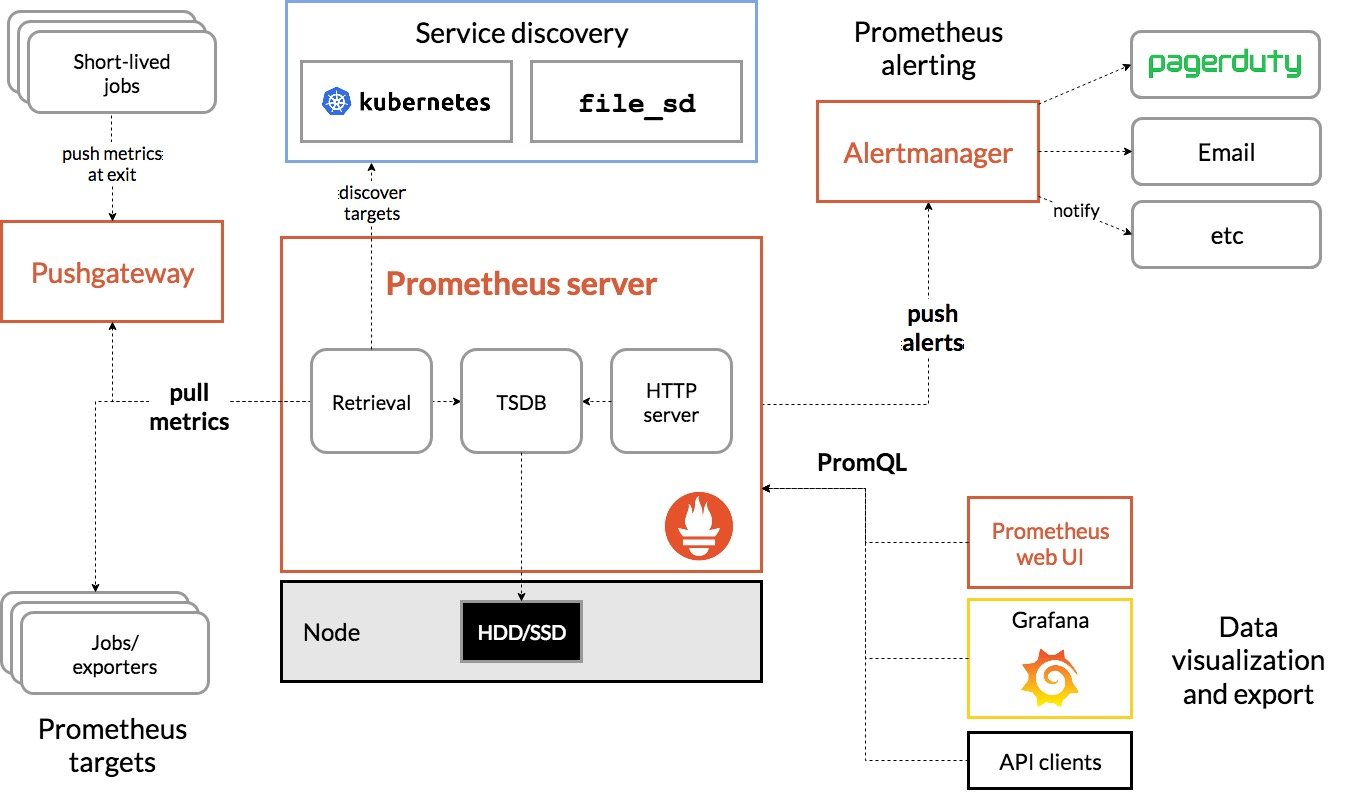
第一次接触Prometheus就被深深吸引,决定阅读源码,了解它的设计方式。首先分析的是pull metrics部分,讨论Prometheus是如何从目标点采集数据的。
第一次接触Prometheus就被深深吸引,决定阅读源码,了解它的设计方式。首先分析的是pull metrics部分,讨论Prometheus是如何从目标点采集数据的。
在调用方与被调方之间设计一个队列,有助于缓冲请求量,平滑处理请求,达到消峰的目的,降低峰值请求对服务性能、可用性的影响和服务失败等问题。有效防止被调方因高负载而产生间歇性的不可用。
很对设计中都会涉及到调用远端云服务,尤其是微服务化的架构,这种调用就更加频繁了。如果被调方出现间歇性的高负载,该服务的性能就会受到影响,为了不造成雪,崩服务如果有弹性设计,可能会选择执行限流或者降级,甚至直接熔断,这肯定是我们最不希望看到的现象。
这种间隙性负载可能出现在什么情况下?
无论是客户端,还是后台,缓存都是重要的组件,缓存主要的目的就是针对提升读多写少的业务场景的性能,现在大多数的业务场景读多写少,并且微服务的架构下,服务之间频繁交互,缓存更是必备的组件。
我们无论怎么提升存储的性能,也无法解决需要依赖计算得出数据的性能问题,比如点赞数,评论数,转发数。其次就像之前文章九、微服务:容错设计之补偿事务)提到的需要检测该用户是否为广告平台注册用户,如果是就去存储中获取该注册用户信息。每打开app一次,就需要去存储中查一次。所有流量直接请求到数据库,数据库很有可能宕机,而且90%的用户不会是广告平台注册的用户。针对这种可以设计一个快照,在redis中存一份唯一的标识id,比如iOS的Idfa。先用缓存挡住大多数的量,只有真实的注册用户才会去存储读详细数据。很简单的业务场景,使用缓存就可以解决性能问题。
注意:本篇主要列出缓存相关的典型问题以及设计重点,其他不做更详细的描述,针对这些注意点,Google一下,很多解决方案。部分篇幅主要以实践,分析go-cache的实现
状态处理在微服务架构中很关键的设计,应用被微服务化后,如果一个功能对应于一个服务的话很难对大流量进行抗压,所以单一功能可能是由一组相同的服务共同抗压的。这种架构设计需要解决的就是上下文状态的处理,或者几个服务组合的业务逻辑状态。
这种状态称之为服务状态,如果做到无状态服务,该服务对于运维执行水平扩容的时候,不必担心出现逻辑混乱的情况。
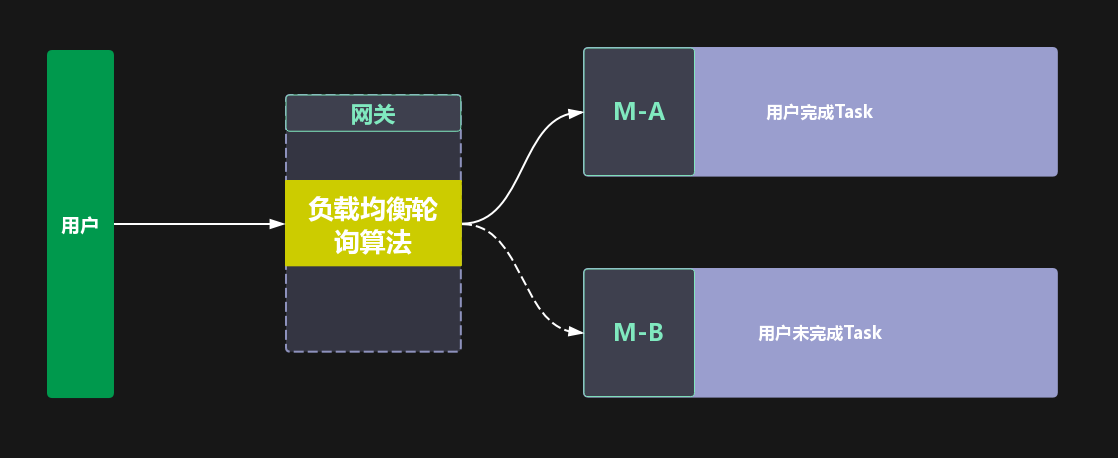
例如,一个用户请求一个活动页,流量请求到M-A服务,并且完成了task,M-A服务记录下该状态,由于流量太大一个服务低挡不住,运维进行了扩容,新扩容一个相同服务M-B,此时该用户再次请求活动页准备领奖,因为负载均衡策略这次请求到了M-B,但是用户却发现task没有完成。
单体服务被拆分为多个服务,调用关系错综复杂,突发大流量很可能把当前一些服务压垮,造成资源的耗尽。甚至直接导致雪崩效应。
服务限流可以把这种突发流量超出处理范围的部分丢弃掉,或者阻塞他们在队列里。避免雪崩。这个时候通过监控机制,我们可以完成扩容等方案,进而处理流量的暴增。
限流为了限制单位时间内最大的处理速度。保证在服务不被压垮的情况下,以最大速率处理请求。一下场景会触发限流